久しぶりのブログ更新ですが、ARでもVRでもないこと書きます。
グラフDBとは
データとデータのつながりの深さをグラフ状のネットワークで表したデータベースです。
と、文章で書いてもイメージが湧きにくいと思うので実物を見せます。
はい、どーん!
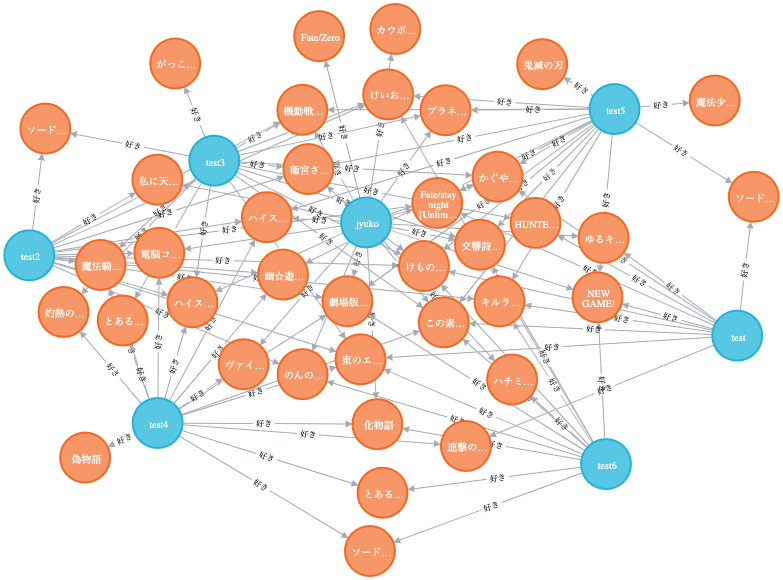
データを表す丸がノード、関係性を示す線がエッジです。
今回試作したグラフDBでは、オレンジのノードがAnimation(アニメ)で青いノードがUser(ユーザ)になります。
Animationにはtitle、Userにはnameというプロパティを持たせています。
ユーザノードとそのユーザが好きなアニメノードを関連付けている訳ですが、リレーション・関係性(Relationship)の名前も自由に付けることができるので、「好き(like)」「見た(watch)」とか直感的なネーミングでリレーションを作成していきます。
何に使うの?
グラフDBの用途として、データの分析・可視化とレコメンドがあります。
データの分析・可視化については最初に載せた図の通りで、検索結果を点と線でグラフとして表示できます。
矢印が多く出ているユーザはたくさんアニメを見ているユーザ、矢印がたくさん入っているアニメは人気のアニメといった具合に、視覚的に情報を見ることで気付きを得られます。
より特徴的な用途がレコメンドで、データの関係性の深さからユーザにオススメ(レコメンド)を提示することができます。
- ◯◯◯をご覧になった あなたへ
- この商品をチェックした人はこんな商品もチェックしています
- △△△さんと他◯人がフォローしています
- 知り合いかも
と同じような機能がグラフDBで実現できます。
Neo4jのインストール
グラフDBを構築するにあたり最も人気が高いデータベースがNeo4jです。というか他のミドルウェアは検索してもほとんど出てこないです。
AWSでシステムを構築しているのであれば、Amazon Neptuneを検討してみてもよいかとは思いますが、Neo4jから学習しておけば間違いないでしょう。
ローカルPC(Macです)で動かすには、homebrewでインストールする方法とDocker(docker-compose)で動かす方法があります。
homebrew、docker-composeの環境構築については割愛しますので、別途検索してください。
homebrewでインストール
brewコマンドでインストールして、neo4j startするだけです。
$ brew install neo4j $ neo4j start
http://localhost:7474 にアクセスするとNeo4jの管理コンソールが開きます。
docker-composeでインストール
まず、docker-compose.ymlを用意します。
- docker-compose.yml
version: '3'
services:
neo4j:
image: neo4j:latest
ports:
- 7474:7474
- 7687:7687
volumes:
- ./neo4j/data:/data
- ./neo4j/logs:/logs
- ./neo4j/conf:/conf
- ./neo4j/import:/import
docker-compose.ymlの置いてあるディレクトリでup -dコマンドを実行します。
$ docker-compose up -d
同様に http://localhost:7474 で管理コンソールにアクセスできます。
管理コンソールからの操作
管理コンソールにログイン
起動したNeo4jの管理コンソールにログインします。
デフォルトのユーザ名/パスワードはneo4j/neo4jです。初回ログイン後にパスワードを変更しましょう。
ログインに成功すると、このような画面が表示されます。

画面上部の赤枠で囲ったところにテキストの入力エリアがあります。ここにSQLによく似たクエリ言語のCypherで記述したコマンドを入力するとグラフDBの操作ができます。
ノードの作成
データ登録しないと始まらないので、1件ずつ作ってみます。
まず、アニメを登録するために以下のクエリを実行します。
$ CREATE (a:Animation{title: 'デカダンス'}) RETURN a

クエリの意味は、Animationというラベルを持つノードaを作成(CREATE)して、結果を表示(RETURN)になります。aはクエリ内の変数のようなもので、データベースにはaという情報は登録されません。
ノードの後ろに{}で囲った部分がノードのプロパティで、アニメのタイトルをtitleというプロパティにセットしています。グラフDBはNoSQLの一種なので、ノードはプロパティを自由に持つことができます。
実行結果をTable表示にすると、JSON形式でプロパティが出力されます。

今度はユーザを作成してみます。ラベルとプロパティが異なるだけです。
$ CREATE (u:User {name: 'jyuko'}) RETURN u

作成したノードを検索するクエリを書くには、CREATEの部分をMATCHに変えます。
ラベルがUser、プロパティのnameがjyukoに一致(MATCH)するノードuを検索して表示(RETURN)します。
条件に一致するノードが複数あればすべて表示されます。
$ MATCH (u:User {name: 'jyuko'}) RETURN u
ノードの削除については、検索のクエリのRETURNをDELETEに変えます。
条件に一致(MATCH)するuを削除(DELETE)です。
$ MATCH (u:User {name: 'jyuko'}) DELETE u
リレーションシップの作成
AnimationノードとUserノードができたので、2つのノードを関連付けます。
$ MATCH (u:User{name: 'jyuko'}),(a:Animation{title: 'デカダンス'})
CREATE (u)-[r:`好き`]->(a)
RETURN u,r,a
クエリの1行目では、MATCHで条件に一致するUserノードとAnimationノードをそれぞれu、aとして検索しています。
このu、aに対して、uがaを好きというリレーションシップrを作成しています。アローになっている->でグラフの接続の向きを表しています。
なので、
CREATE (u)-[r:`好き`]->(a)
は
CREATE (a)<-[r:`好き`]-(u)
と書いても同じ結果です。ノードの順序が違いますが、接続の方向が同じだからです。
クエリを実行すると以下の結果を得られます。2つのノードが接続されていることがひと目でわかると思います。

CSVからの一括登録
ここまで1件ずつデータを登録してきましたが、流石につらいので、CSVを使って一括で登録することにします。
1行目をヘッダとしてプロパティ名を入れ、2行目以降にデータを書いていきます。
- animations.csv
title NEW GAME! カウボーイビバップ のんのんびより ...
作成したCSVはNeo4jのファイルシステムのimportディレクトリに置きます。
ローカルで実行している場合、docker-compose.ymlで指定したパスかホーム直下あたりにneo4jディレクトリが作成されているはずです。
neo4jディレクトリを見つけたら、その下にimportディレクトリを作成し、CSVファイルを配置します。

LOAD CSVを使って一括登録を行います。
$ LOAD CSV WITH HEADERS FROM 'file:///animations.csv' AS line
CREATE (a:Animation{title: line.title})
ヘッダ付きCSVから1行ずつデータを読み込んで、Animationノードを作成しています。lineがCSVの行データでline.titleにCSVでtitle列に入力した名称が入ります。
ノードだけでなくリレーションシップもCSVから作成できます。
以下のようなCSVを用意して、importディレクトリに配置します。
- likes.csv
user_name,animation_title jyuko,NEW GAME! jyuko,のんのんびより ...
実行するクエリは以下にようになります。
$ LOAD CSV WITH HEADERS FROM 'file:///likes.csv' AS line
MATCH (u:User{name: line.user_name}),(a:Animation{title: line.animation_title})
CREATE (u)-[r:`好き`]->(a)
CSVを使わないクエリと比較すると、LOAD CSVで取得したlineのデータを使って、1件ごとのクエリを作成していることがわかります。
レコメンド検索してみる
データが用意できたので、レコメンド検索的なクエリを投げてみます。
テストDBで、あるアニメ(ハイスコアガール)を好きな人にオススメのアニメを検索します。
$ MATCH (a:Animation{title:'ハイスコアガール'})<-[:`好き`]-(u:User)-[r:`好き`]->(reccomend:Animation)
RETURN reccomend, count(r)
ORDER BY count(r) DESC
MATCHの条件がちょっと長いですが、前半でハイスコアガールを好きなユーザuを抽出しています。uは1人のユーザーではなくハイスコアガールを好きという条件で集められたユーザグループです。
さらにuが好きな他のアニメをreccomendとして検索して、「好き」が多い順(rが多い = count(r))で並べています。
クエリの実行結果はこのようになります。上位に来ているアニメがこのデータベースに基づくオススメです。

検索条件は同じでcountをせずにグラフで可視化してみます。
MATCH (a:Animation{title:'ハイスコアガール'})<-[:`好き`]-(u:User)-[r:`好き`]->(reccomend:Animation)
RETURN a,u,r,reccomend

title: ハイスコアガールのノードを好きと登録されたUserノードが4つあり、それぞれ他のアニメにも好きの矢印が伸びています。なかでも図の中央にあるグループは4人中3人以上が好きとしているアニメでレコメンドの上位に来ていることがわかります。
このようにユーザの行動履歴(見た、買った、お気に入りにした、フォローした)に基づいたグラフDBを構築することでオススメを検索しています。
自分は見ていない(知らない)対象でも、他者を介した関係性の強さでオススメができる点が面白いところです。
APIの利用
ここまでCSVインポートを含めて管理コンソールから操作してきましたが、サービスに組み込む際にはAPI経由でCypherのクエリを実行する形になります。
Neo4jのバージョン3.5以前ではHTTP API、4.x以降ではCypher transaction APIと呼ばれるAPIです。
HTTP APIとCypher transaction APIはほぼ同等のAPIですが、リクエストURIが異なります。
例として、トランザクションを開始するAPIは以下となります。
- HTTP API
- Cypher transaction API
リクエストのヘッダに認証情報、ボディにCypherでクエリを書きます。
ボディのstatementsは配列形式となっており、複数のCypherクエリをまとめて実行することもできます。
検索のクエリを1件だけ投げる例です。
{
"statements": [
{
"statement": "MATCH (u:User{name: 'jyuko'}),(a:Animation{title:'デカダンス'}) RETURN u,a"
}
]
}
上記に対して、レスポンスボディのJSONは以下のようになります。
resultsにCypherの実行結果が入っています。
{
"commit": "http://localhost:7474/db/data/transaction/1/commit",
"results": [
{
"columns": [
"u",
"a"
],
"data": [
{
"row": [
{
"password": "test1234",
"name": "jyuko"
},
{
"title": "デカダンス"
}
],
"meta": [
{
"id": 125,
"type": "node",
"deleted": false
},
{
"id": 262,
"type": "node",
"deleted": false
}
]
}
]
}
],
"transaction": {
"expires": "Fri, 23 Oct 2020 17:57:38 +0000"
},
"errors": []
}
この例は検索だけなのでここで終わりですが、データの登録や削除を行う場合、commitのリクエストを投げて処理を確定する必要があります。このあたりは一般的なデータベースのトランザクションの概念と同じです。
レスポンスのcommitに含まれているURL(上記例で言うと、http://localhost:7474/db/data/transaction/1/commit)にPOSTリクエストを行うとcommitされ、DELETEリクエストを行うとrollbackされます。
- POST http://localhost:7474/db/data/transaction/1/commit
- commitされる
- DELETE http://localhost:7474/db/data/transaction/1/commit
- rollbackする
また、トランザクションには期限があり、transactionのexpiresを過ぎると自動でrollbackします。
トランザクション作成とコミットを同時に行う(オートコミット)を行うこともできます。
その場合は、トランザクション開始時のリクエストURIにcommitを付けます。
- HTTP API
- Cypher transaction API
RDBMSを扱ったことのある方ならわかると思いますが、関係性を扱うデータベースにおいてトランザクションを管理できることは重要で、API経由でもコントロールできるのは非常に便利です。
まとめ
グラフDBのNeo4jを使うと、データ分析やレコメンド検索のためのデータベースが簡単に構築できます。
環境構築の容易さもさることながら、クエリ言語のCypherが特に優秀で、複雑な検索条件を直感的にスラスラと記述でき、使っていて気持ちがいいです。
API経由でもCypherのクエリを投げられる点もいいですね。
グラフDBは、動画や音楽の配信、ECサイト、SNSやマッチングサービスなど様々なサービス・システムで活用できるはずなので、頭の片隅に入れておくといいんじゃないかなと思います。
おわりに
記事内に出てきているアニメは、私のオススメだったりします。
あと、次回はARかVR(WebVR)やります。